Image source: DL Notes: Advanced Gradient Descent
Adam (short for Adaptive Moment Estimation) was introduced by Diederik Kingma and Jimmy Ba in 2015 [1], and quickly became the go-to optimizer in deep learning. This article explains why a fixed learning rate fails, what Adam does differently, and how it works — from first principles to code.
The Problem with a Fixed Learning Rate
The "One Speed Fits All" Dilemma
Imagine you're hiking through a mountain range with one strict rule: every step you take must be exactly the same length — no more, no less.
On a steep cliff face, that fixed step length is terrifying — one step too large and you tumble. On a long, gentle slope to the valley, that same step feels absurdly tiny — it would take forever to reach the bottom.
This is exactly the problem with a fixed learning rate in gradient descent:
The single scalar controls the step size for every parameter — whether that parameter has large gradients or tiny ones, whether it's converging well or oscillating wildly.
Three Ways a Fixed Learning Rate Fails
1. Too Large — Overshooting
When is too large, gradient descent overshoots the minimum and bounces back and forth:
The loss never decreases — it oscillates forever around the minimum.
2. Too Small — Crawling Forever
When is too small, learning works but is painfully slow:
Thousands of iterations just to move a little. In practice with millions of parameters, this is computationally catastrophic.
3. The "Ravine" Problem — Oscillation
In higher dimensions, loss landscapes often look like narrow ravines — very steep in one direction, nearly flat in another. With a fixed learning rate:
- The steep direction demands a small to avoid oscillating across the ravine walls.
- The flat direction needs a large to make any progress along the ravine floor.
No single fixed can satisfy both at the same time. LeCun et al. [2] provide an early and thorough analysis of these pathological loss-landscape behaviours and their impact on convergence.
The Core Pain
Different parameters need different step sizes. A fixed learning rate treats all of them the same — and that's the bottleneck.
Enter Adam: The GPS of Optimizers
If vanilla gradient descent is hiking with a fixed stride, Adam is using a GPS with adaptive routing: it speeds up on highways, slows down in tight corners, and remembers which paths were already explored.
Adam's secret is tracking two things per parameter at every step:
| Quantity | Symbol | Intuition |
|---|---|---|
| 1st Moment (momentum) | Which direction have gradients been pointing recently? | |
| 2nd Moment (adaptive scale) | How large have the gradients been recently? |
By dividing by the square root of the 2nd moment, Adam automatically shrinks the step size for parameters with consistently large gradients and enlarges it for parameters with small gradients.
Building Adam from Scratch
Step 1 — Momentum: Smoothing the Direction
The problem it solves: Gradients are noisy. Every mini-batch gives a slightly different gradient. Chasing each individual noisy gradient makes the path jagged.
The idea: Keep a running average of past gradients, like a ball rolling downhill — it builds speed in a consistent direction and isn't thrown off by small bumps.
Where:
- = current gradient
- = decay rate, typically 0.9 (90% weight on the past, 10% on the new gradient)
Analogy: It's like computing a weighted average of recent directions. Gradient yesterday counts more than gradient from 10 steps ago. Sutskever et al. [3] demonstrated that this momentum term is critical for fast, stable convergence in deep networks.
Step 2 — Adaptive Scale: Normalizing by History
The problem it solves: Some parameters have consistently large gradients; others have tiny ones. We want large-gradient parameters to take smaller steps, and small-gradient parameters to take larger steps.
The idea: Track the running average of squared gradients:
Where:
- = decay rate, typically 0.999
A parameter that always receives large gradients will accumulate a large . Dividing the step size by keeps its updates proportionally small. This is Adam's per-parameter learning rate.
Step 3 — Bias Correction: Fixing Cold-Start Errors
The problem it solves: Since and , the first few estimates of and are heavily biased toward zero (we haven't accumulated enough history yet).
The fix: Divide by to correct for the initial bias:
As grows, , so the correction factor and has no effect — it only matters in the early steps.
Step 4 — The Final Update Rule
Where prevents division by zero.
Default hyperparameters from the original paper [1]:
| Hyperparameter | Symbol | Default |
|---|---|---|
| Learning rate | 0.001 | |
| 1st moment decay | 0.9 | |
| 2nd moment decay | 0.999 | |
| Numerical stability |
Worked Example: Adam in Action
Let's trace Adam manually on the same simple function we used for gradient descent:
Starting at , with default hyperparameters (, , , ).
Initialize: , .
Step :
Step :
With bias correction and update, .
Notice: Adam makes consistent, controlled steps — not as aggressive as large- SGD (which would have overshot), yet much faster than tiny- SGD (which would crawl). The bias-corrected estimates keep early steps meaningful despite the cold start.
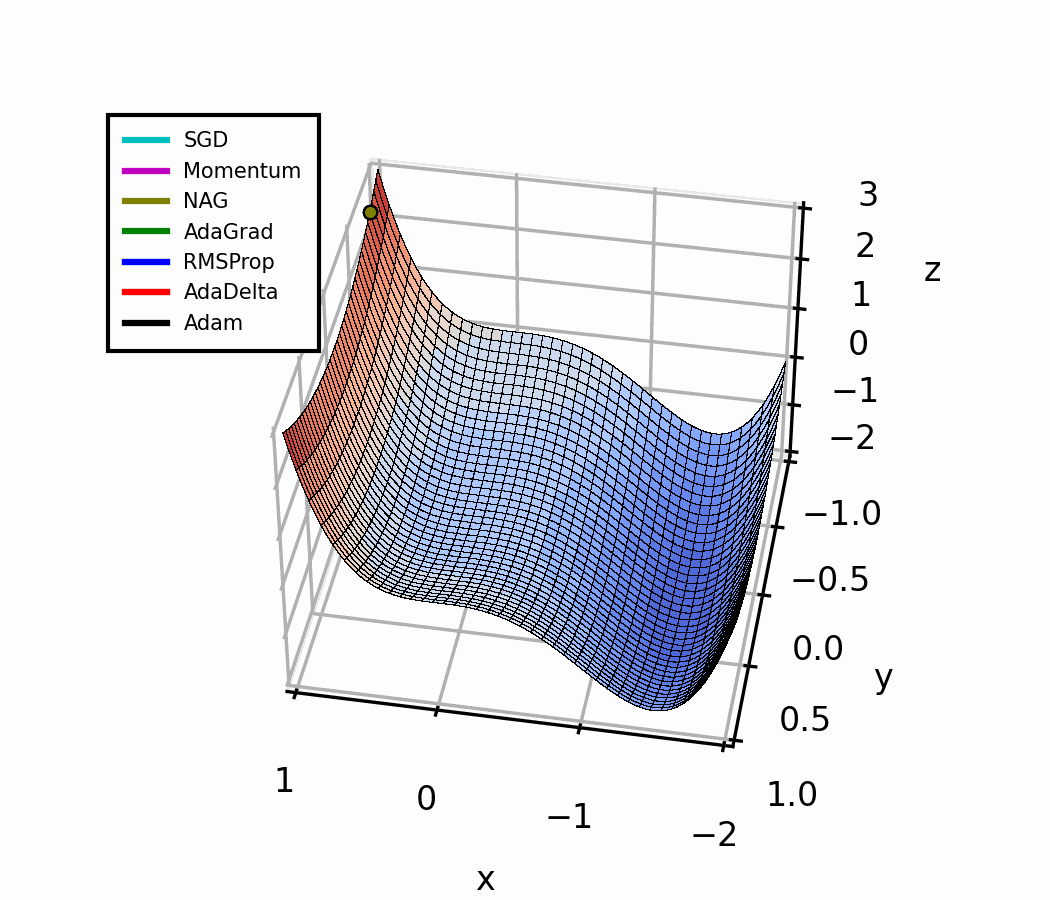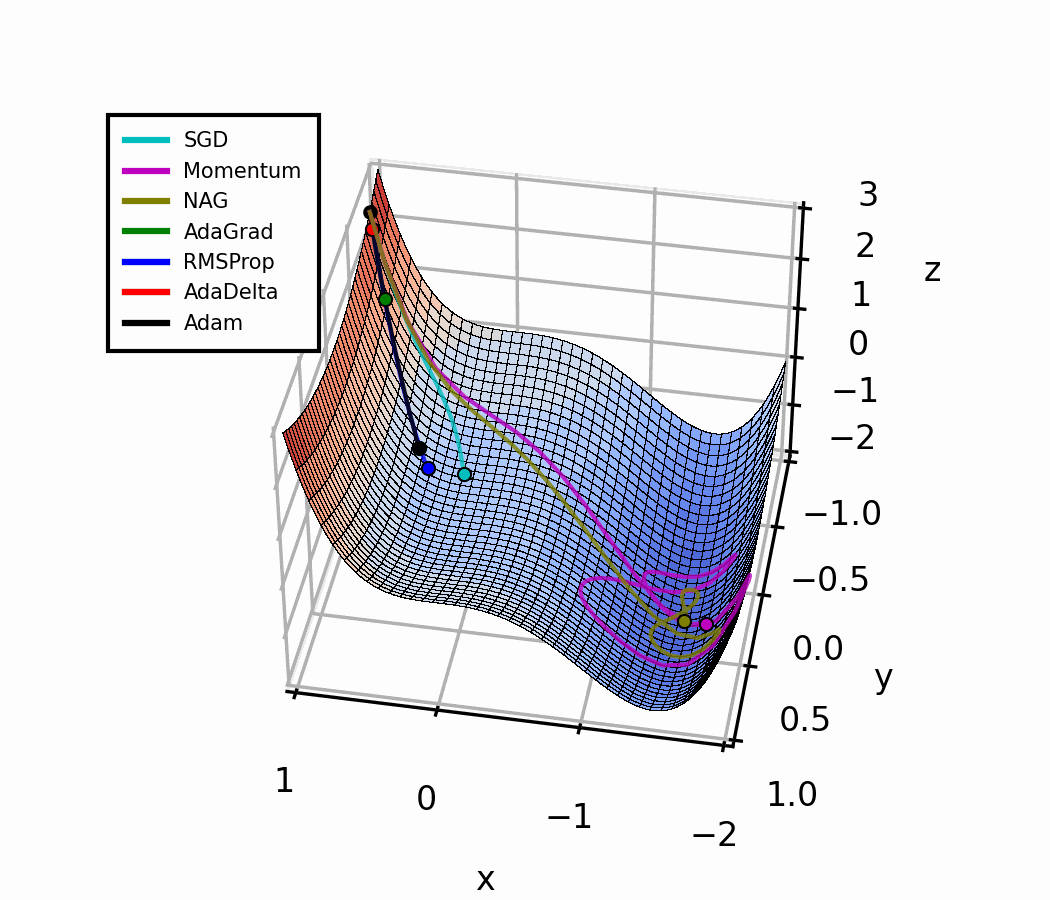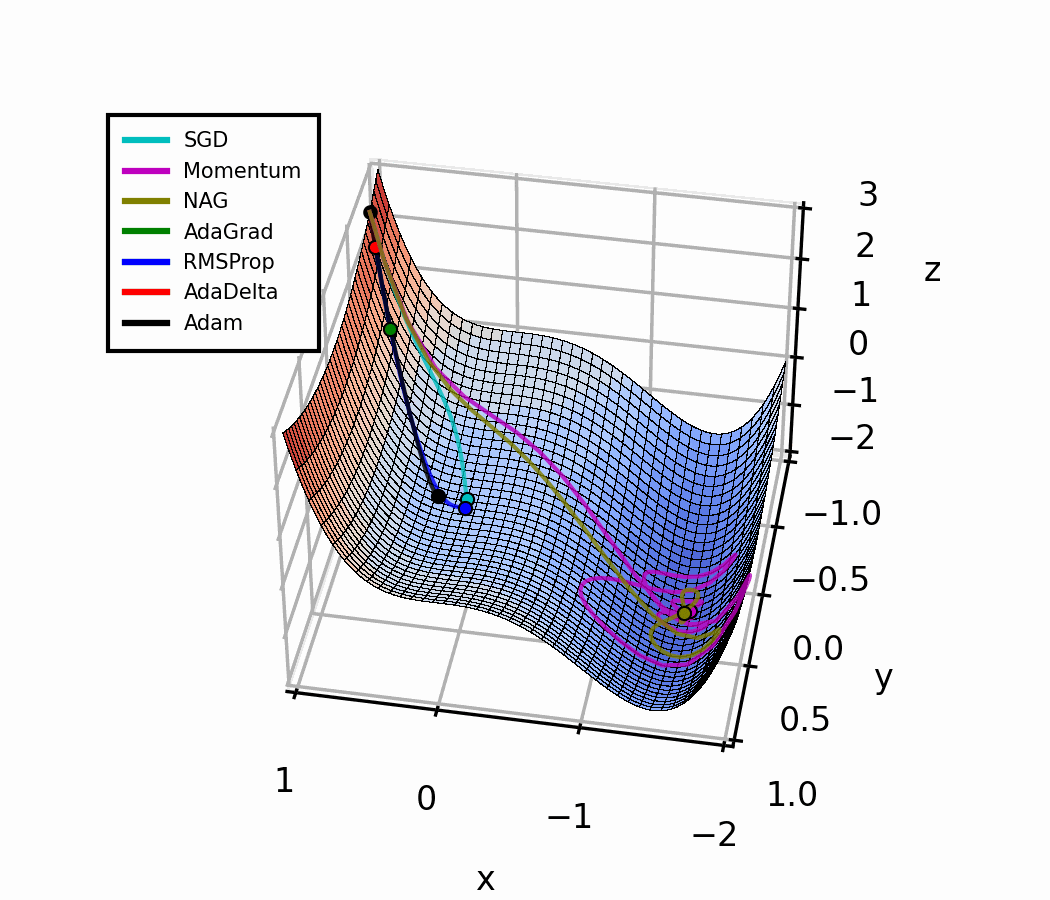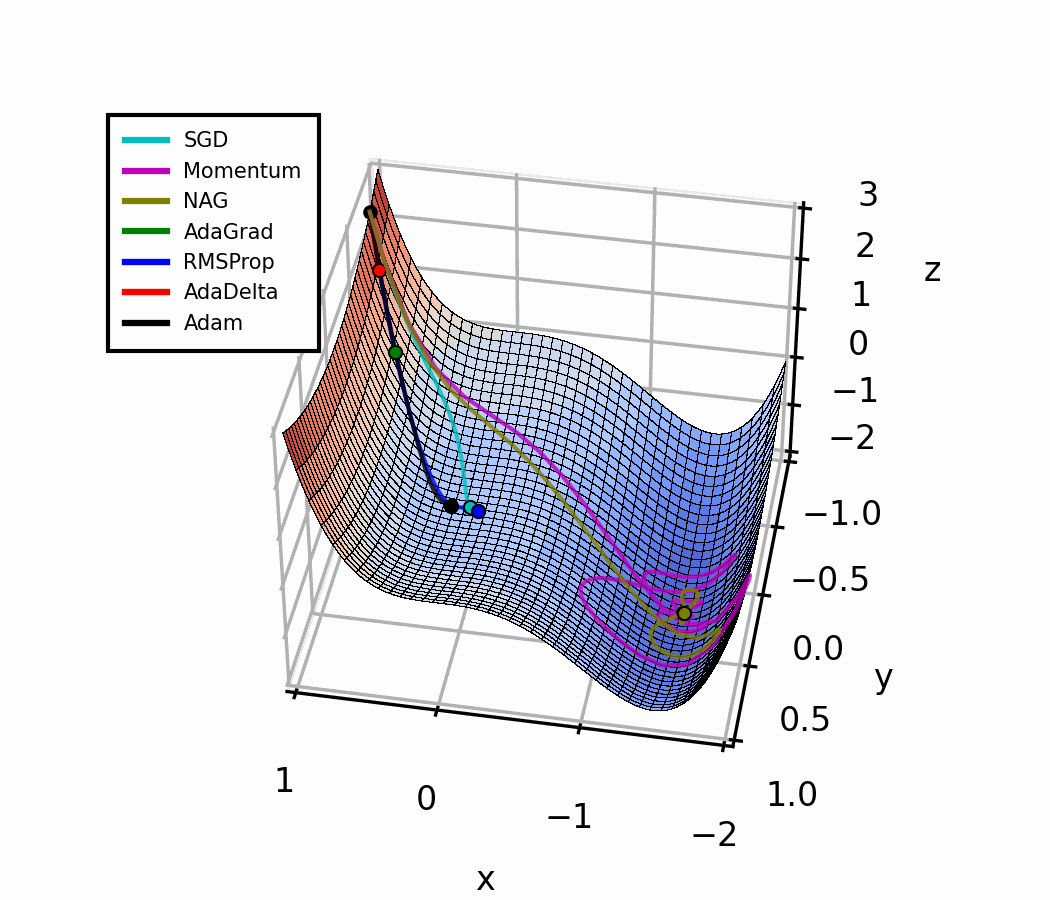
Comparing Optimizers Side by Side
Let's bring it all together with intuition:
| Optimizer | Step size | Memory | Strengths | Weaknesses |
|---|---|---|---|---|
| SGD | Fixed | None | Simple, well-understood | Sensitive to , slow on ravines |
| SGD + Momentum | Fixed | Gradient direction | Faster, smoother path | Still needs good |
| RMSProp [4] | Adaptive | Gradient magnitude | Good for non-stationary | No momentum |
| Adam | Adaptive | Direction + magnitude | Best of both worlds | Can generalize slightly worse |
All four optimizers start at the same position with the same learning rate α. Watch how adaptive methods (RMSProp, Adam) handle steep gradients automatically — no manual tuning needed.
Controls
Current Loss
Optimization Landscape (3D)
Loss Comparison
Adam Internal State (x-component)
Trace how bias correction shrinks as t grows — the 1/(1−β^t) factor approaches 1 and vanishes
Adam essentially combines SGD with momentum (1st moment) and RMSProp (2nd moment) under one roof, with bias correction on top.
Python Implementation
Minimal Adam from Scratch
import numpy as np
def adam(grad_fn, theta_init, alpha=0.001, beta1=0.9, beta2=0.999, eps=1e-8, max_iters=1000):
theta = theta_init
m = 0.0 # first moment (momentum)
v = 0.0 # second moment (adaptive scale)
for t in range(1, max_iters + 1):
g = grad_fn(theta) # ① compute gradient
m = beta1 * m + (1 - beta1) * g # ② update 1st moment
v = beta2 * v + (1 - beta2) * g ** 2 # ③ update 2nd moment
m_hat = m / (1 - beta1 ** t) # ④ bias-correct 1st moment
v_hat = v / (1 - beta2 ** t) # ⑤ bias-correct 2nd moment
theta = theta - alpha / (np.sqrt(v_hat) + eps) * m_hat # ⑥ update
if abs(g) < 1e-7:
print(f"Converged at step {t}")
break
return theta
# Minimize J(θ) = θ², ∇J(θ) = 2θ
theta_min = adam(grad_fn=lambda th: 2 * th, theta_init=5.0)
print(f"Minimum at θ = {theta_min:.8f}")
Output:
Converged at step 817
Minimum at θ = 0.00000001
Adam on Linear Regression
Now let's apply Adam to a real use case — fitting a line to data.
import numpy as np
def adam_linear_regression(X, y, alpha=0.01, beta1=0.9, beta2=0.999,
eps=1e-8, epochs=200):
m = len(y)
w, b = 0.0, 0.0
# Separate Adam state for each parameter
mw, vw = 0.0, 0.0 # moments for w
mb, vb = 0.0, 0.0 # moments for b
for t in range(1, epochs + 1):
y_pred = w * X + b
error = y_pred - y
# Gradients (same formula as gradient descent)
gw = (2 / m) * np.dot(error, X)
gb = (2 / m) * np.sum(error)
# 1st and 2nd moment updates for w
mw = beta1 * mw + (1 - beta1) * gw
vw = beta2 * vw + (1 - beta2) * gw ** 2
mw_hat = mw / (1 - beta1 ** t)
vw_hat = vw / (1 - beta2 ** t)
# 1st and 2nd moment updates for b
mb = beta1 * mb + (1 - beta1) * gb
vb = beta2 * vb + (1 - beta2) * gb ** 2
mb_hat = mb / (1 - beta1 ** t)
vb_hat = vb / (1 - beta2 ** t)
# Parameter updates
w = w - alpha / (np.sqrt(vw_hat) + eps) * mw_hat
b = b - alpha / (np.sqrt(vb_hat) + eps) * mb_hat
if t % 50 == 0:
loss = np.mean(error ** 2)
print(f"Epoch {t:4d}: loss={loss:.6f} w={w:.4f} b={b:.4f}")
return w, b
# True relationship: y = 2x + 1
X = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
y = np.array([3.0, 5.0, 7.0, 9.0, 11.0])
w, b = adam_linear_regression(X, y)
print(f"\nFitted: ŷ = {w:.4f}·x + {b:.4f}")
Output:
Epoch 50: loss=0.000042 w=1.9953 b=1.0044
Epoch 100: loss=0.000000 w=2.0000 b=1.0000
Epoch 150: loss=0.000000 w=2.0000 b=1.0000
Epoch 200: loss=0.000000 w=2.0000 b=1.0000
Fitted: ŷ = 2.0000·x + 1.0000
Adam recovers the true cleanly and fast — especially compared to vanilla gradient descent, which required careful learning rate tuning.
When to Use Adam
Adam is a safe default for most deep learning tasks:
- Neural networks: Training MLPs, CNNs, Transformers, RNNs
- Noisy gradients: Mini-batch training with small batch sizes
- Sparse features: NLP tasks where some words appear rarely (large, infrequent gradients)
- Getting started: When you don't want to spend time tuning the learning rate
One Known Limitation
Wilson et al. [5] show that adaptive optimizers like Adam can converge to slightly worse generalization than well-tuned SGD with momentum for image classification. In that setting, SGD + momentum with learning rate scheduling can outperform Adam. But for most tasks, Adam's robustness wins.
Summary
| Concept | Key Idea |
|---|---|
| Fixed learning rate flaw | One for all parameters — too rigid |
| Momentum () | Smooth gradient direction over time |
| Adaptive scale () | Scale steps by gradient magnitude history |
| Bias correction | Fix cold-start bias when |
| Adam update |
Adam doesn't remove the learning rate — it still matters. But it makes training dramatically less sensitive to your choice of . That's why the same default of works well across an enormous variety of tasks.
If gradient descent is hiking with a fixed stride, Adam is hiring a GPS-equipped guide who adjusts your pace, smooths your path, and makes sure you don't waste time on terrain you've already explored.
References
- D. P. Kingma and J. Ba, "Adam: A method for stochastic optimization," in Proc. 3rd Int. Conf. Learn. Representations (ICLR), San Diego, CA, USA, May 2015. [Online]. Available: https://arxiv.org/abs/1412.6980
- Y. LeCun, L. Bottou, G. B. Orr, and K.-R. Müller, "Efficient backprop," in Neural Networks: Tricks of the Trade, G. B. Orr and K.-R. Müller, Eds. Berlin, Germany: Springer, 1998, pp. 9–50. [Online]. Available: https://link.springer.com/chapter/10.1007/978-3-642-35289-8_5
- I. Sutskever, J. Martens, G. Dahl, and G. Hinton, "On the importance of initialization and momentum in deep learning," in Proc. 30th Int. Conf. Mach. Learn. (ICML), Atlanta, GA, USA, Jun. 2013, pp. 1139–1147. [Online]. Available: https://proceedings.mlr.press/v28/sutskever13.html
- T. Tieleman and G. Hinton, "Lecture 6.5 — RMSProp: Divide the gradient by a running average of its recent magnitude," COURSERA: Neural Networks for Machine Learning, Tech. Rep., 2012.
- A. C. Wilson, R. Roelofs, M. Stern, N. Srebro, and B. Recht, "The marginal value of momentum for small learning rate SGD," in Proc. 31st Conf. Neural Inf. Process. Syst. (NeurIPS), Long Beach, CA, USA, Dec. 2017. [Online]. Available: https://arxiv.org/abs/1705.08292