រូបភាពយកមកពី: DL Notes: Advanced Gradient Descent
ការប្រើ Gradient descent គឺពិតជាមានប្រសិទ្ធភាព ប៉ុន្តែវាមានបញ្ហាមួយ៖ រាល់គ្រប់ Parameter (ប៉ារ៉ាម៉ែត្រ) ទាំងអស់នៅក្នុងម៉ូឌែលរបស់អ្នក ប្រើប្រាស់ Learning Rate (ទំហំជំហាន) តែមួយដូចគ្នា។ ហើយការកំណត់លេខនោះឱ្យបានត្រឹមត្រូវ? វាដូចជាការទស្សន៍ទាយច្រើនជាងវិទ្យាសាស្ត្រ។
Adam (មកពីពាក្យថា Adaptive Moment Estimation) ត្រូវបានណែនាំដោយលោក Diederik Kingma និង Jimmy Ba ក្នុងឆ្នាំ ២០១៥ [1] ហើយវាបានក្លាយជា "Optimizer" ដ៏ពេញនិយមបំផុតក្នុងវិស័យ Deep Learning។ អត្ថបទនេះនឹងពន្យល់ថា ហេតុអ្វី បានជាការប្រើ Learning Rate ថេរតែមួយមិនសូវល្អ, តើ Adam ធ្វើអ្វីខ្លះខុសពីគេ, និង របៀប ដែលវាដំណើរការ — ចាប់ពីទ្រឹស្តីរហូតដល់កូដជាក់ស្តែង។
បញ្ហានៃការប្រើ Learning Rate ថេរ (Fixed Learning Rate)
វិបត្តិ "ទំហំជំហានមួយ ប្រើគ្រប់កន្លែង"
សាកស្រមៃថាអ្នកកំពុងដើរភ្នំដោយមានច្បាប់ដ៏តឹងរឹងមួយ៖ រាល់ជំហានដែលអ្នកបោះ ត្រូវតែមានប្រវែងស្មើៗគ្នាជានិច្ច — មិនឱ្យលើស មិនឱ្យខ្វះ។
នៅពេលអ្នកនៅលើច្រាំងថ្មចោត ការបោះជំហានវែងពេកអាចឱ្យអ្នកធ្លាក់ជ្រោះ។ ប៉ុន្តែនៅពេលអ្នកនៅលើវាលទំនាបដែលមានជម្រាលតិចតួច ការបោះជំហានដដែលនោះមានអារម្មណ៍ថាយឺតខ្លាំងណាស់ — វាអាចនឹងចំណាយពេលរាប់ឆ្នាំទើបទៅដល់បាតភ្នំ។
នេះគឺជាបញ្ហាពិតប្រាកដនៃ Learning Rate ថេរ () នៅក្នុង Gradient Descent៖
តម្លៃ តែមួយនេះ គ្រប់គ្រងទំហំជំហានសម្រាប់ គ្រប់ Parameter ទាំងអស់ — ទោះបីជា Parameter ខ្លះត្រូវការបោះជំហានធំ ឬខ្លះត្រូវការបោះជំហានតូចក៏ដោយ។
ផលវិបាក ៣ យ៉ាងនៃ Learning Rate ថេរ
១. ធំពេក — រំលងគោលដៅ (Overshooting)
នៅពេល ធំពេក វានឹងធ្វើឱ្យយើងបោះជំហានរំលងចំណុចទាបបំផុត (Minimum) ហើយលោតទៅលោតមក៖ ការបាត់បង់ (Loss) មិនដែលថយចុះឡើយ — វានឹងលោតចុះឡើងជុំវិញគោលដៅរហូត។
២. តូចពេក — យឺតដូចអណ្តើក (Crawling)
នៅពេល តូចពេក ការរៀនដំណើរការទៅមុខមែន ប៉ុន្តែវាយឺតខ្លាំងណាស់។ ក្នុងម៉ូឌែលដែលមាន Parameter រាប់លាន នេះគឺជាមហន្តរាយខាងពេលវេលា និងកម្លាំងម៉ាស៊ីន។
៣. បញ្ហា "ផ្លូវតូចចង្អៀត" (Ravine Problem)
នៅក្នុងលំហវិមាត្រខ្ពស់ ក្រាហ្វជម្រាលជារឿយៗមើលទៅដូចជា ជ្រលងភ្នំដ៏តូចចង្អៀត — ចោតខ្លាំងក្នុងទិសដៅម្ខាង និងរាបស្មើក្នុងទិសដៅម្ខាងទៀត។
- ទិសដៅដែលចោត ត្រូវការ តូច ដើម្បីកុំឱ្យបោះជំហានបុកជញ្ជាំងជ្រលងភ្នំ។
- ទិសដៅដែលរាបស្មើ ត្រូវការ ធំ ដើម្បីដើរឱ្យទៅមុខឆាប់ដល់។ មិនមាន ថេរណាមួយ អាចបំពេញចិត្តទិសដៅទាំងពីរក្នុងពេលតែមួយបានទេ។ LeCun et al. [2] បានធ្វើការវិភាគលម្អិតពីបទប្បញ្ញត្តិ Loss Landscape ទាំងនេះ និងផលប៉ះពាល់របស់ពួកវាទៅលើការ Convergence។
ចំណុចខ្សោយសំខាន់
Parameter ផ្សេងគ្នា ត្រូវការទំហំជំហានផ្សេងគ្នា។ Learning rate ថេរចាត់ទុកពួកវាដូចគ្នាទាំងអស់ — ហើយនេះគឺជាបញ្ហាកកស្ទះ។
ស្គាល់ Adam: ប្រព័ន្ធ GPS នៃ Optimizer
បើ Gradient Descent ធម្មតាគឺជាការដើរភ្នំដោយបោះជំហានថេរ Adam គឺជាការប្រើ GPS ដែលមានការណែនាំផ្លូវដោយវៃឆ្លាត៖ វាបង្កើនល្បឿននៅលើផ្លូវហាយវេ បន្ថយល្បឿននៅផ្លូវបត់ចង្អៀត និងចងចាំផ្លូវដែលធ្លាប់បានដើរកន្លងមក។
អាថ៌កំបាំងរបស់ Adam គឺការតាមដាន រឿងពីរយ៉ាង សម្រាប់រាល់ Parameter នីមួយៗ៖
| បរិមាណ | និមិត្តសញ្ញា | អត្ថន័យងាយៗ |
|---|---|---|
| 1st Moment (Momentum) | តើទិសដៅណាខ្លះដែលជម្រាល (Gradients) ធ្លាប់ចង្អុលទៅនាពេលថ្មីៗនេះ? | |
| 2nd Moment (Adaptive Scale) | តើជម្រាល (Gradients) មានទំហំ ធំប៉ុនណា នាពេលថ្មីៗនេះ? |
តាមរយៈការចែកទំហំជំហាននឹងឫសការ៉េនៃ 2nd moment, Adam នឹងបន្ថយទំហំជំហានដោយស្វ័យប្រវត្តិសម្រាប់ Parameter ណាដែលមានជម្រាលធំៗខ្លាំងពេក និងបង្កើនទំហំជំហានសម្រាប់ Parameter ណាដែលមានជម្រាលតូចៗ។
របៀបបង្កើត Adam (ជំហានម្តងៗ)
ជំហានទី ១ — Momentum: រក្សាល្បឿន និងទិសដៅ
បញ្ហាដែលវាដោះស្រាយ: ជម្រាល (Gradients) ជារឿយៗមានភាពរំខាន (Noisy)។ ការរត់តាមជម្រាលដែលរំខានទាំងនោះ ធ្វើឱ្យផ្លូវដើរមិនរលូន។
គំនិត: រក្សាមធ្យមភាគនៃជម្រាលពីមុនៗ ដូចជាការរមៀលបាល់ចុះពីលើភ្នំ — វានឹងបង្កើនល្បឿនក្នុងទិសដៅដែលស្របគ្នា និងមិនងាយងាករេដោយសារដុំថ្មតូចៗតាមផ្លូវ។
- ជាមេគុណ (ជាទូទៅគឺ 0.9)៖ មានន័យថាឱ្យតម្លៃ ៩០% លើអតីតកាល និង ១០% លើជម្រាលថ្មី។
Sutskever et al. [3] បានបង្ហាញថា Momentum term នេះ មានសារៈសំខាន់ខ្លាំងណាស់ក្នុងការ Converge យ៉ាងលឿន និងស្ថិតស្ថេរ នៅក្នុង Deep Networks។
ជំហានទី ២ — Adaptive Scale: ការបត់បែនតាមប្រវត្តិ
បញ្ហាដែលវាដោះស្រាយ: Parameter ខ្លះមានជម្រាលធំ ខ្លះមានជម្រាលតូច។ យើងចង់ឱ្យអាធំដើរតិចៗ និងអាតូចដើរឱ្យបានច្រើន។
គំនិត: តាមដានមធ្យមភាគនៃ "ការ៉េ" នៃជម្រាល៖
Parameter ណាដែលទទួលបានជម្រាលធំៗជាបន្តបន្ទាប់ នឹងមានតម្លៃ ធំ។ នៅពេលយើងយកជំហានទៅចែកនឹង វានឹងធ្វើឱ្យការ Update ថយចុះមកតូចវិញ។ នេះហើយជា Learning Rate ផ្ទាល់ខ្លួន សម្រាប់ Parameter នីមួយៗ។
ជំហានទី ៣ — Bias Correction: ការកែតម្រូវពេលចាប់ផ្តើម
បញ្ហាដែលវាដោះស្រាយ: ដោយសារនៅពេលចាប់ផ្តើម និង នោះការប៉ាន់ស្មានដំបូងៗនឹងខិតទៅជិតសូន្យខ្លាំងពេក (វាមិនទាន់មានប្រវត្តិគ្រប់គ្រាន់)។
ដំណោះស្រាយ: ចែកវាជាមួយ ដើម្បីកែតម្រូវឱ្យមានតុល្យភាពវិញនៅជំហានដំបូងៗ៖
ជំហានទី ៤ — រូបមន្តចុងក្រោយនៃការ Update
(ចំណាំ៖ ដើម្បីការពារកុំឱ្យមានការចែកនឹងសូន្យ)
Hyperparameters លំនាំដើមតាមក្រដាសសំណើដើម [1]:
| Hyperparameter | និមិត្តសញ្ញា | Default |
|---|---|---|
| Learning rate | 0.001 | |
| 1st moment decay | 0.9 | |
| 2nd moment decay | 0.999 | |
| Numerical stability |
ឧទាហរណ៍ជាក់ស្តែង: Adam ដំណើរការ
សូមតាមដាន Adam ដោយដៃ លើអនុគមន៍សាមញ្ញដូចដែលយើងប្រើក្នុង Gradient Descent:
ចាប់ផ្តើមនៅ ជាមួយ hyperparameters លំនាំដើម (, , , )។
ចាប់ផ្តើម: , ។
ជំហាន :
ជំហាន :
បន្ទាប់ពី Bias Correction និង Update, ។
Adam ធ្វើ ជំហានស្ថិតស្ថេរ និងគ្រប់គ្រងបាន — មិនរហ័សហ្លើតដូច SGD ដែល ធំ (ដែលនឹងបោះជំហានរំលងចំណុចទាប) ប៉ុន្តែលឿនជាងច្រើនពី SGD ដែល តូចខ្លាំង (ដែលនឹងដើរយឺតបន្តិចម្ដងៗ)។ ការកែ Bias Correction ធ្វើឱ្យជំហានដំបូងៗនៅតែមានន័យ ទោះបីចាប់ផ្តើមពី Cold Start ក៏ដោយ។
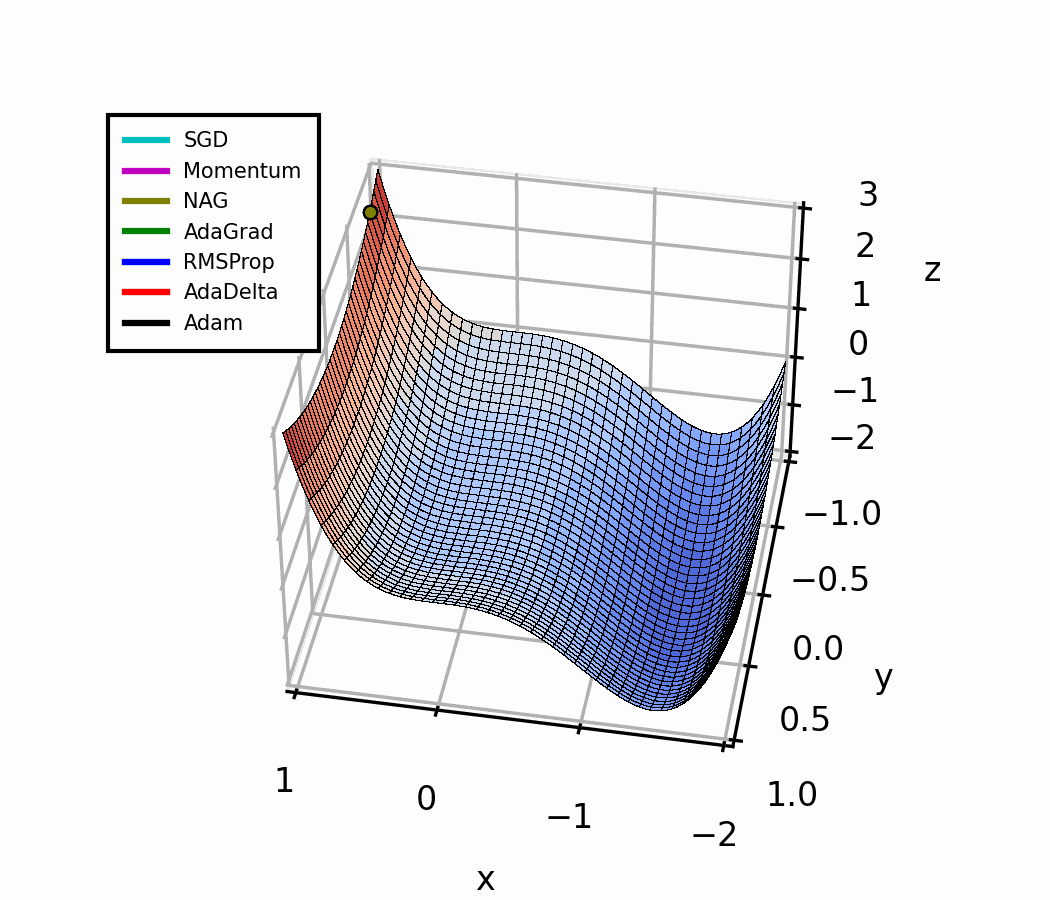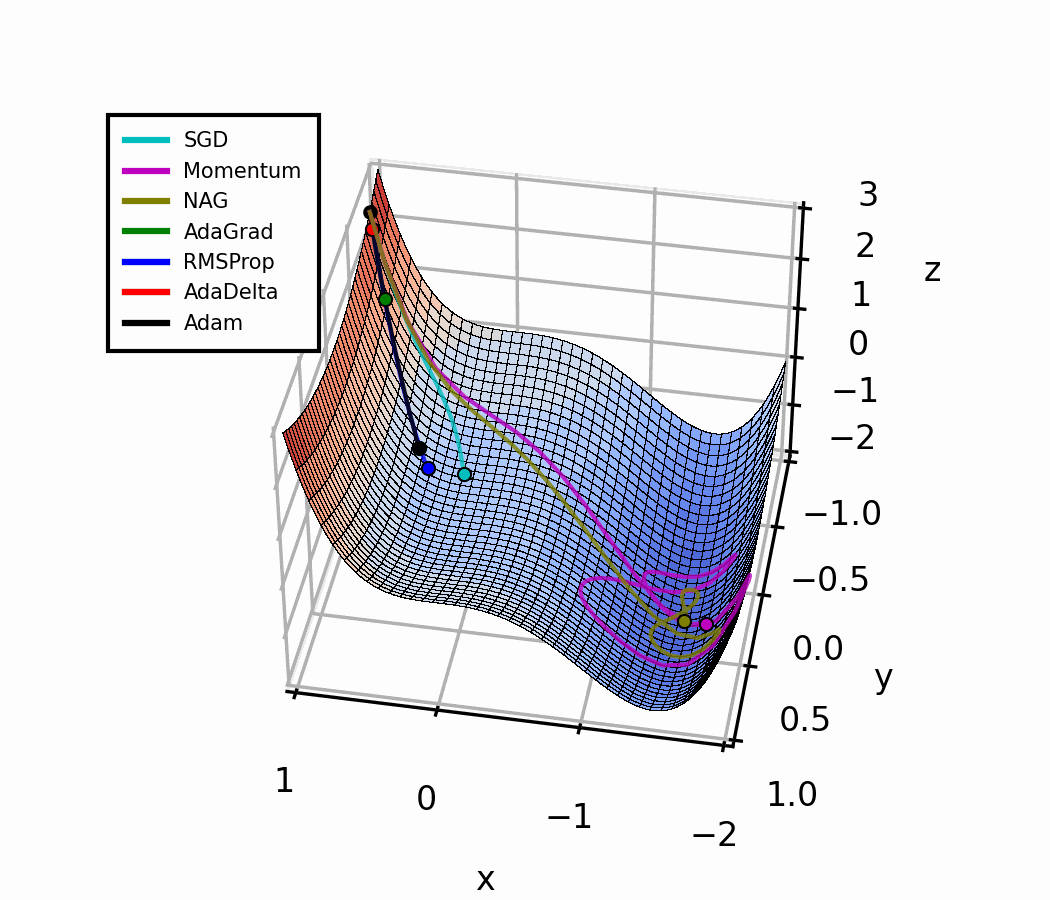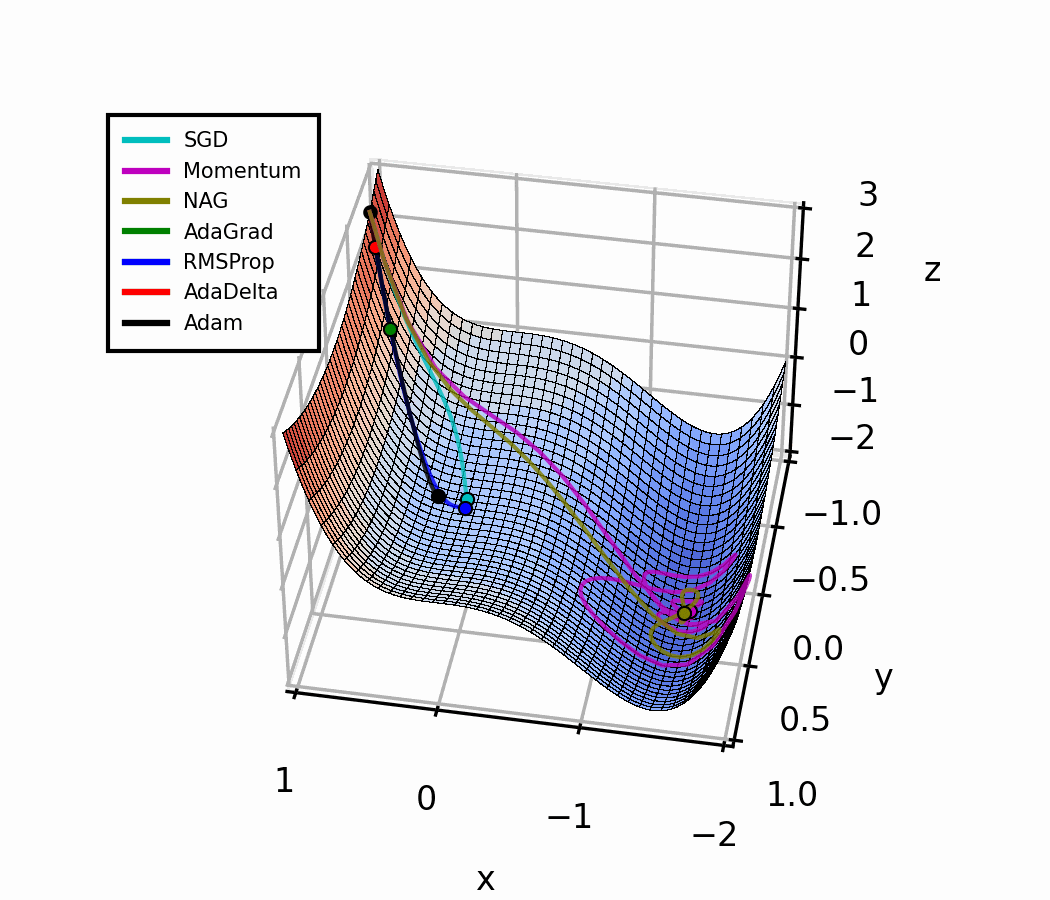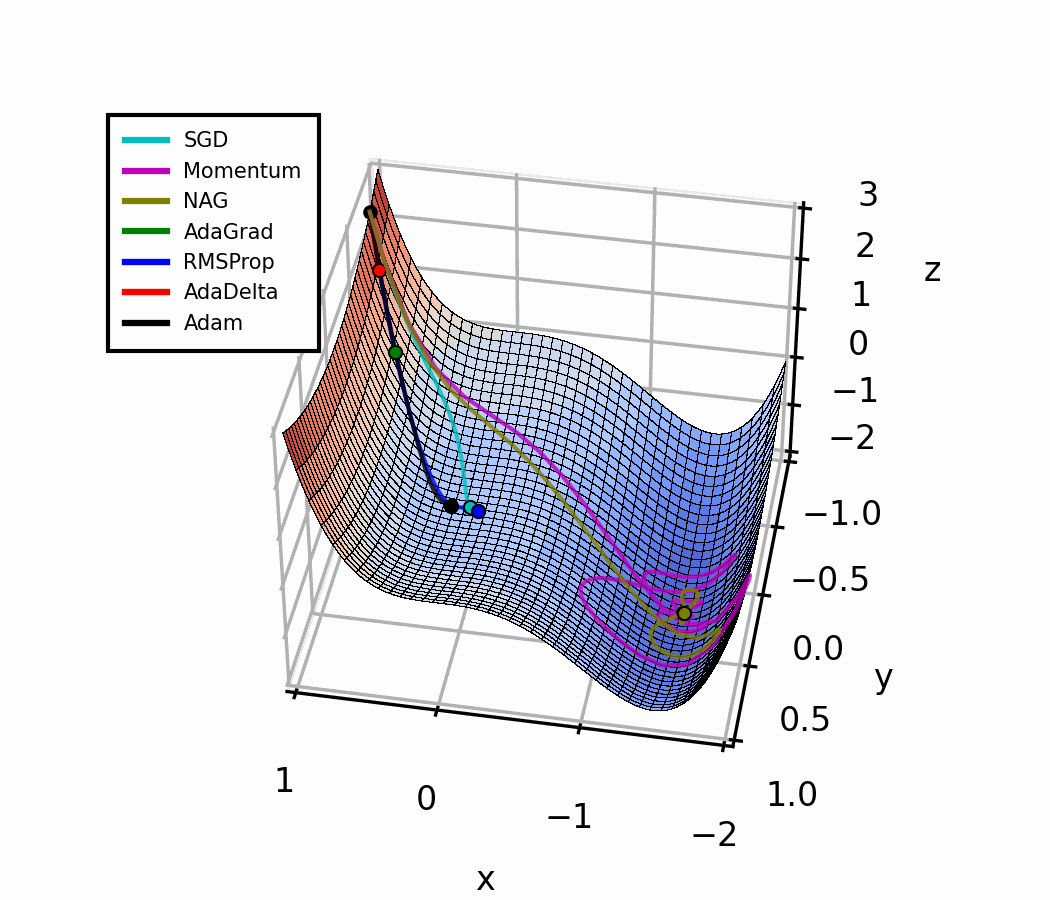
ការប្រៀបធៀប Optimizer
| Optimizer | ទំហំជំហាន | ការចងចាំ | ចំណុចខ្លាំង | ចំណុចខ្សោយ |
|---|---|---|---|---|
| SGD | ថេរ () | គ្មាន | សាមញ្ញ ងាយយល់ | ពិបាកកំណត់ , យឺត |
| SGD + Momentum | ថេរ () | ទិសដៅជម្រាល | ដើរលឿន និងរលូនជាង | នៅតែត្រូវការ ល្អ |
| RMSProp [4] | បត់បែន | ទំហំជម្រាល | ល្អក្នុងករណីទិន្នន័យផ្លាស់ប្ដូរ | គ្មាន Momentum |
| Adam | បត់បែន | ទិសដៅ + ទំហំ | ល្អបំផុតសឹងគ្រប់ការងារ | ពេលខ្លះ Generalize បានមិនល្អប៉ុណ្ណឹង |
Optimizer ទាំងបួននេះ ចាប់ផ្ដើមពីទីតាំង និង learning rate α ដូចគ្នា។ សំគាល់ ពីរបៀបដែល adaptive method (RMSProp, Adam) ដោះស្រាយ gradient ខ្ទង់ ដោយស្វ័យប្រវត្ត — គ្មានការ tune ដោយដៃ ទាល់ ត្រូវ ។
ការកំណត់
ស្ថិតិ
Optimization Landscape (3D)
Loss (កាន់តែតូចមានន័យថា កំពុងខិតជិតអប្បបរមា)
ស្ថានភាពខ្នាតក្នុង Adam (អ័ក្ស x)
តាមដានអថឹការ bias correction អស់ក្វានៅពើល t ធ្វើ — 1/(1−β^t) ខិតត័ក 1
Adam បញ្ចូលរួម SGD + Momentum (1st moment) និង RMSProp (2nd moment) ក្នុងក្របខណ្ឌតែមួយ ជាមួយ Bias Correction ជាការបន្ថែម។
ការអនុវត្តជាមួយ Python (កូដគំរូ)
Adam យ៉ាងសាមញ្ញពីបាតដៃទទេ
ខាងក្រោមនេះគឺជាការសរសេរ Adam Optimizer ដោយខ្លួនឯង (ពីបាតដៃទទេ)៖
import numpy as np
def adam(grad_fn, theta_init, alpha=0.001, beta1=0.9, beta2=0.999, eps=1e-8, max_iters=1000):
theta = theta_init
m = 0.0 # 1st moment (momentum)
v = 0.0 # 2nd moment (adaptive scale)
for t in range(1, max_iters + 1):
g = grad_fn(theta) # ① គណនា gradient
m = beta1 * m + (1 - beta1) * g # ② update 1st moment
v = beta2 * v + (1 - beta2) * g ** 2 # ③ update 2nd moment
m_hat = m / (1 - beta1 ** t) # ④ កែតម្រូវ bias សម្រាប់ m
v_hat = v / (1 - beta2 ** t) # ⑤ កែតម្រូវ bias សម្រាប់ v
# ⑥ ធ្វើការ Update parameter
theta = theta - alpha / (np.sqrt(v_hat) + eps) * m_hat
if abs(g) < 1e-7:
print(f"ជោគជ័យនៅជំហានទី {t}")
break
return theta
# សាកល្បងកាត់បន្ថយ J(θ) = θ², ∇J(θ) = 2θ
theta_min = adam(grad_fn=lambda th: 2 * th, theta_init=5.0)
print(f"ចំណុចទាបបំផុតគឺ θ = {theta_min:.8f}")
លទ្ធផល:
ជោគជ័យនៅជំហានទី 817
ចំណុចទាបបំផុតគឺ θ = 0.00000001
Adam លើ Linear Regression
សូមសាកអនុវត្ត Adam លើករណីប្រើប្រាស់ជាក់ស្តែង — ការ Fit ខ្សែត្រង់ ទៅទិន្នន័យ។
import numpy as np
def adam_linear_regression(X, y, alpha=0.01, beta1=0.9, beta2=0.999,
eps=1e-8, epochs=200):
m = len(y)
w, b = 0.0, 0.0
# Adam state ដាច់ដោយឡែកសម្រាប់ parameter នីមួយៗ
mw, vw = 0.0, 0.0 # moments for w
mb, vb = 0.0, 0.0 # moments for b
for t in range(1, epochs + 1):
y_pred = w * X + b
error = y_pred - y
# Gradients (រូបមន្តដូចគ្នានឹង Gradient Descent)
gw = (2 / m) * np.dot(error, X)
gb = (2 / m) * np.sum(error)
# 1st និង 2nd moment updates សម្រាប់ w
mw = beta1 * mw + (1 - beta1) * gw
vw = beta2 * vw + (1 - beta2) * gw ** 2
mw_hat = mw / (1 - beta1 ** t)
vw_hat = vw / (1 - beta2 ** t)
# 1st និង 2nd moment updates សម្រាប់ b
mb = beta1 * mb + (1 - beta1) * gb
vb = beta2 * vb + (1 - beta2) * gb ** 2
mb_hat = mb / (1 - beta1 ** t)
vb_hat = vb / (1 - beta2 ** t)
# Parameter updates
w = w - alpha / (np.sqrt(vw_hat) + eps) * mw_hat
b = b - alpha / (np.sqrt(vb_hat) + eps) * mb_hat
if t % 50 == 0:
loss = np.mean(error ** 2)
print(f"Epoch {t:4d}: loss={loss:.6f} w={w:.4f} b={b:.4f}")
return w, b
# ទំនាក់ទំនងពិត: y = 2x + 1
X = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
y = np.array([3.0, 5.0, 7.0, 9.0, 11.0])
w, b = adam_linear_regression(X, y)
print(f"\nFitted: ŷ = {w:.4f}·x + {b:.4f}")
លទ្ធផល:
Epoch 50: loss=0.000042 w=1.9953 b=1.0044
Epoch 100: loss=0.000000 w=2.0000 b=1.0000
Epoch 150: loss=0.000000 w=2.0000 b=1.0000
Epoch 200: loss=0.000000 w=2.0000 b=1.0000
Fitted: ŷ = 2.0000·x + 1.0000
Adam ស្ដារ បានច្បាស់លាស់ និងលឿន — ជាពិសេសបើប្រៀបនឹង Gradient Descent ធម្មតា ដែលត្រូវបន្ដ Tune Learning Rate ដោយប្រុងប្រយ័ត្ន។
ពេលណាគួរប្រើ Adam?
Adam គឺជាជម្រើសដ៏សុវត្ថិភាពបំផុតសម្រាប់កិច្ចការ Deep Learning ស្ទើរតែទាំងអស់៖
- Neural networks: Training MLPs, CNNs, Transformers, RNNs
- ទិន្នន័យដែលមានការរំខាន (Noisy gradients): ល្អសម្រាប់ Mini-batch training ដែលប្រើ Batch size តូចៗ។
- ទិន្នន័យរំដោចខ្ចាត (Sparse features): ល្អសម្រាប់ NLP ដែលពាក្យខ្លះបង្ហាញកម្រ (ជម្រាលធំ ប៉ុន្តែមិនសូវញឹកញាប់)។
- អ្នកទើបចាប់ផ្តើម: នៅពេលអ្នកមិនចង់ចំណាយពេលច្រើនក្នុងការ Tune Learning Rate។
ចំណាំមួយ
Wilson et al. [5] បង្ហាញថា Adaptive optimizer ដូចជា Adam អាចនឹង Generalize បានន ចុះបន្តិចបើប្រៀបនឹង SGD + Momentum ដែល Tune ល្អ សម្រាប់ Image Classification។ ក្នុងករណីនោះ SGD + Momentum ជាមួយ Learning Rate Scheduling អាចប្រសើរជាង Adam។ ប៉ុន្តែសម្រាប់កិច្ចការភាគច្រើន ភាពរឹងមាំ (Robustness) របស់ Adam នៅតែឈ្នះ។
សេចក្តីសង្ខេប
| គំនិត | ចំណុចសំខាន់ |
|---|---|
| ចំណុចខ្សោយ Fixed LR | តែមួយសម្រាប់ Parameters ទាំងអស់ — លម្អិតពេក |
| Momentum () | ធ្វើឱ្យទិសជម្រាលរលូន និងស្ថិតស្ថេរតាមពេល |
| Adaptive scale () | Scale ជំហានតាមប្រវត្តិទំហំជម្រាល |
| Bias correction | កែ Cold-start bias នៅពេល |
| Adam update |
Adam មិនមែនមកលុបបំបាត់ Learning Rate () នោះទេ — វានៅតែសំខាន់។ ប៉ុន្តែ Adam ធ្វើឱ្យការហ្វឹកហាត់ម៉ូឌែល មិនសូវរងឥទ្ធិពលខ្លាំង ពីការកំណត់លេខ ខុស។ នេះជាមូលហេតុដែលតម្លៃ Default 0.001 របស់វា ដំណើរការបានយ៉ាងល្អលើម៉ូឌែលរាប់ពាន់ខុសៗគ្នា។
បើ Gradient Descent គឺជាការដើរភ្នំដោយបោះជំហានស្មើៗគ្នា Adam គឺជាការជួលអ្នកនាំផ្លូវដែលមាន GPS ជាប់ខ្លួន ដែលចេះកែសម្រួលល្បឿនតាមស្ថានភាពផ្លូវ និងធានាថាអ្នកនឹងមិនដើរវង្វេង ឬចំណាយពេលឥតប្រយោជន៍លើផ្លូវដែលធ្លាប់ដើររួចនោះទេ។
ឯកសារយោង
- D. P. Kingma and J. Ba, "Adam: A method for stochastic optimization," in Proc. 3rd Int. Conf. Learn. Representations (ICLR), San Diego, CA, USA, May 2015. [Online]. Available: https://arxiv.org/abs/1412.6980
- Y. LeCun, L. Bottou, G. B. Orr, and K.-R. Müller, "Efficient backprop," in Neural Networks: Tricks of the Trade, G. B. Orr and K.-R. Müller, Eds. Berlin, Germany: Springer, 1998, pp. 9–50. [Online]. Available: https://link.springer.com/chapter/10.1007/978-3-642-35289-8_5
- I. Sutskever, J. Martens, G. Dahl, and G. Hinton, "On the importance of initialization and momentum in deep learning," in Proc. 30th Int. Conf. Mach. Learn. (ICML), Atlanta, GA, USA, Jun. 2013, pp. 1139–1147. [Online]. Available: https://proceedings.mlr.press/v28/sutskever13.html
- T. Tieleman and G. Hinton, "Lecture 6.5 — RMSProp: Divide the gradient by a running average of its recent magnitude," COURSERA: Neural Networks for Machine Learning, Tech. Rep., 2012.
- A. C. Wilson, R. Roelofs, M. Stern, N. Srebro, and B. Recht, "The marginal value of momentum for small learning rate SGD," in Proc. 31st Conf. Neural Inf. Process. Syst. (NeurIPS), Long Beach, CA, USA, Dec. 2017. [Online]. Available: https://arxiv.org/abs/1705.08292