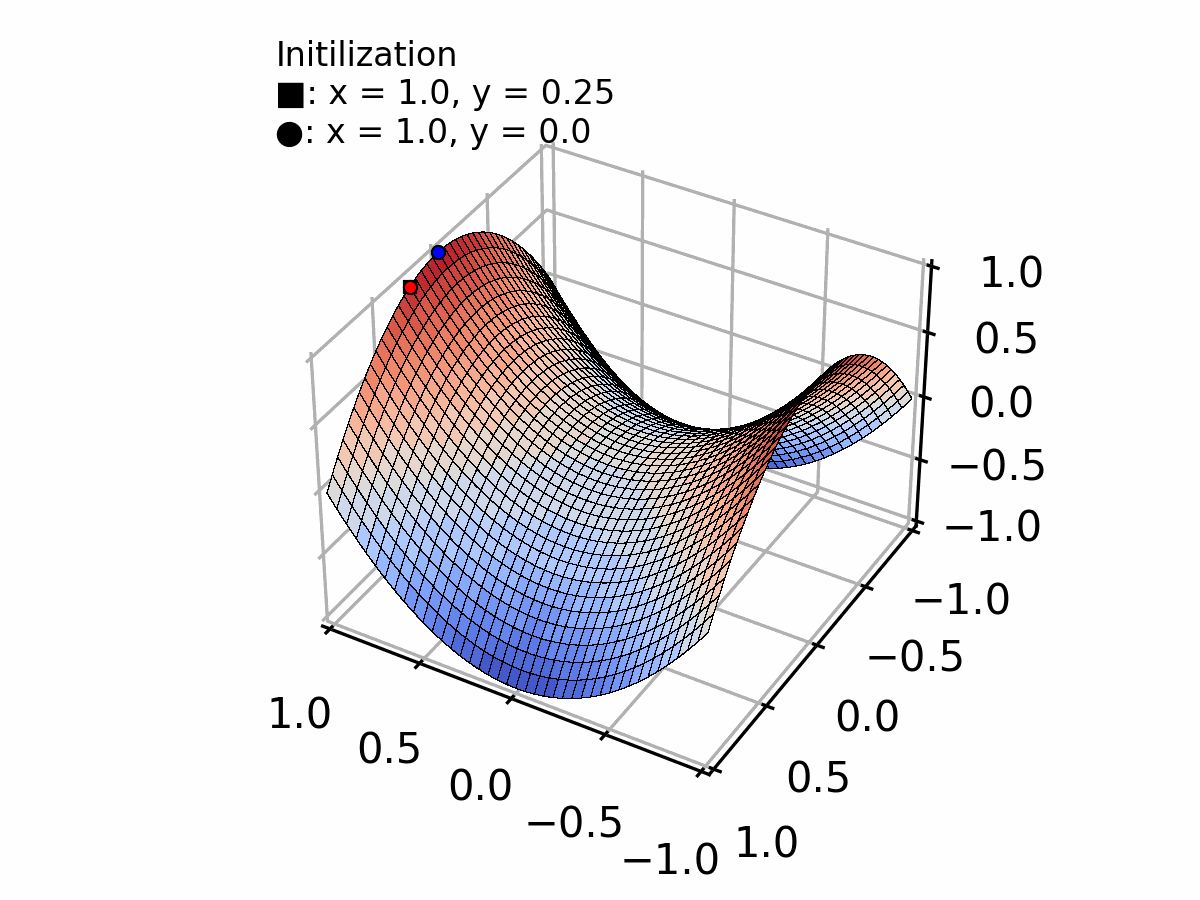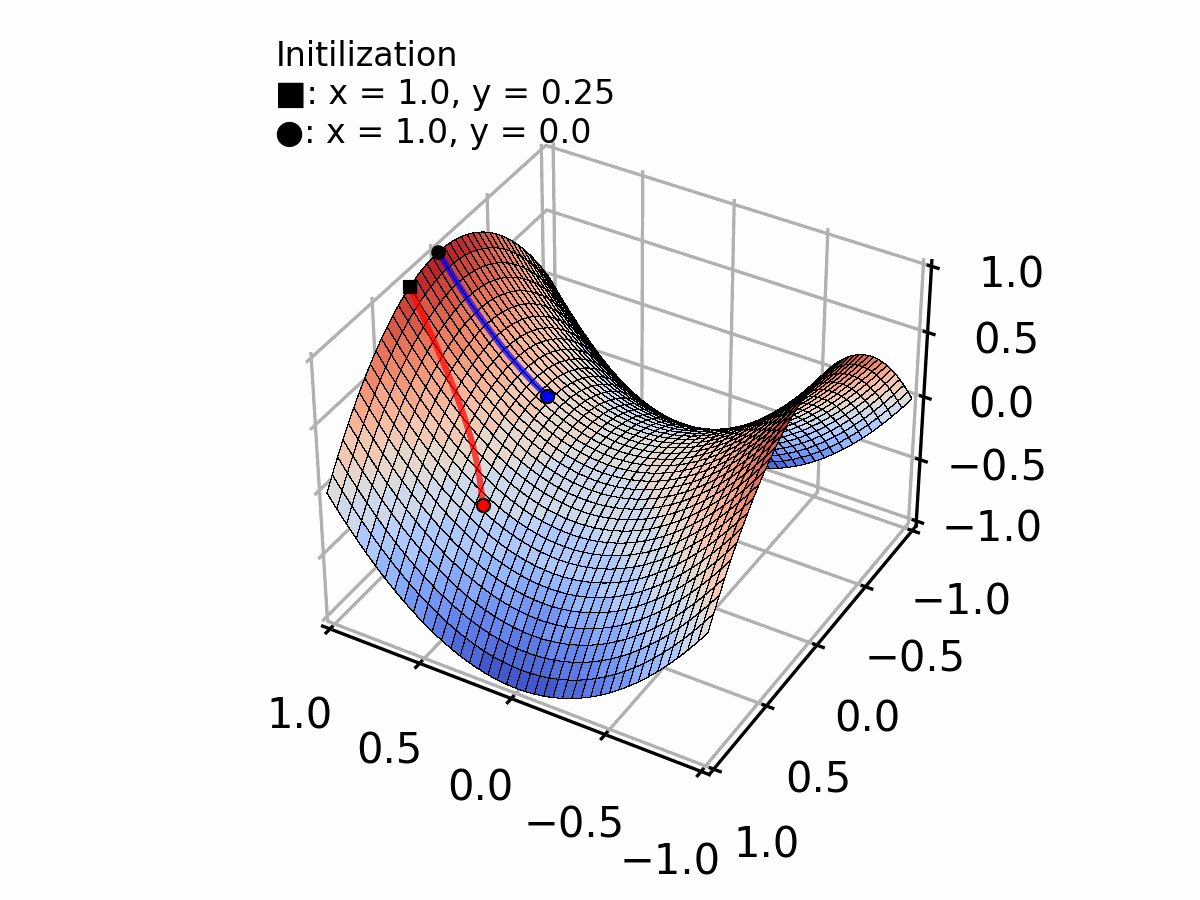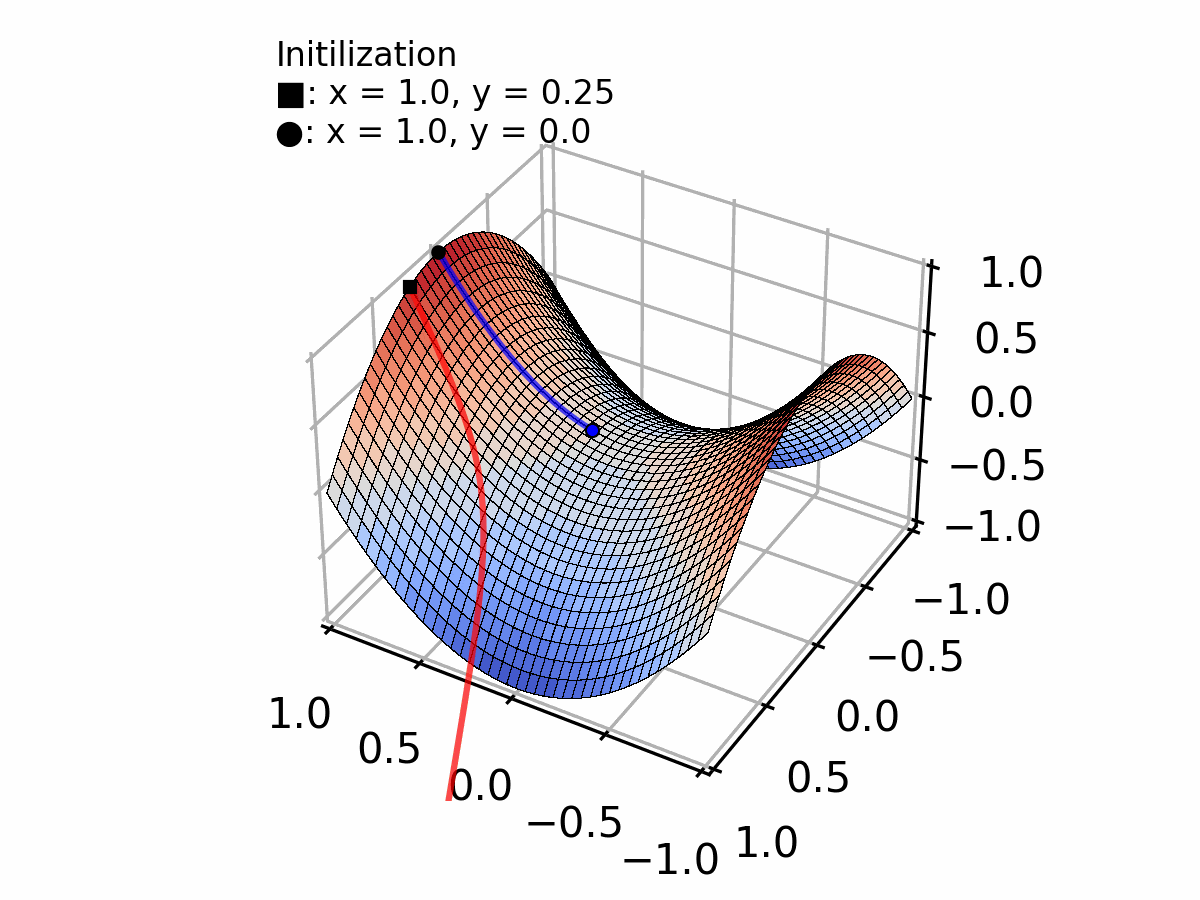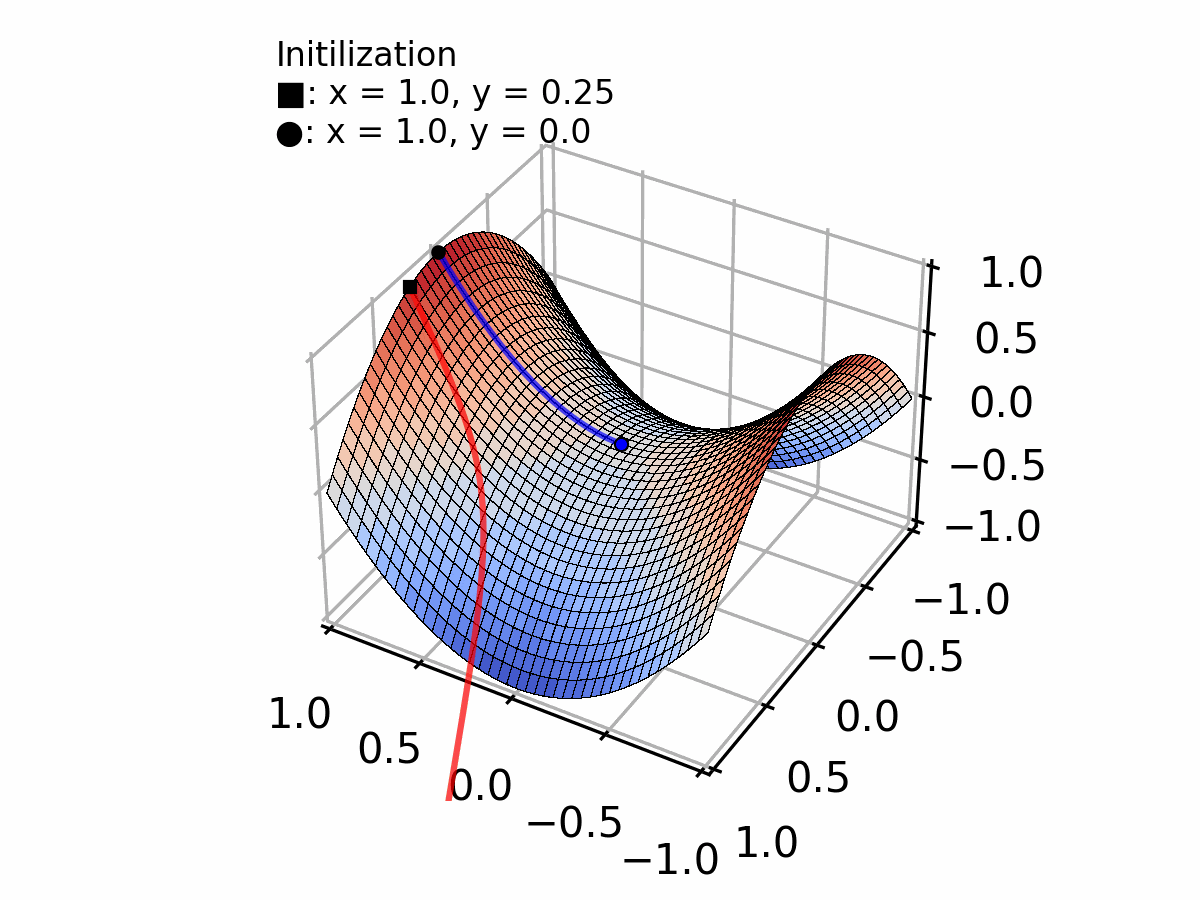
រូបភាពយកមកពី: Creating a Gradient Descent Animation in Python
Gradient Descent គឺជា optimization algorithm មូលដ្ឋានមួយ ក្នុងចំណោម algorithms ដែលមាននៅក្នុង machine learning។ វាជាវិធីសាស្រ្តសម្រាប់ស្វែងរកតម្លៃអប្បបរមានៃអនុគមន៏ ដោយដើរម្តងមួយជំហាន (iteration) ជាបន្តបន្ទាប់ក្នុងទិសដៅ ដែលធ្វើឲ្យអនុគមន៏កាន់តែតូចទៅៗ។
ប្រៀបធៀបលេងៗ
ស្រមៃថា អ្នកកំពុងឈរនៅលើភ្នំមួយដែលមានអ័ព្ទក្រាស់ ហើយអ្នកចង់ទៅជ្រលងខាងក្រោម។ អ្នកមិនអាចមើលឃើញឆ្ងាយទេដោយសារមានអ័ព្ទក្រាស់ពេក ប៉ុន្តែអ្នកនៅបាតជើងរបស់អ្នក អាចដឹងថាកំពុងចុះជ្រៅទៅៗ រឺ ឡើងខ្ពង់ទៅៗ តាមរយៈជម្រោលចោត ។ Gradient descent ធ្វើរការដូចគ្នានេះដែរ: វាធ្វើម្តងមួយជំហានតូចៗចុះក្រោម តាមផ្លូវចម្រោងបំផុត រហូតដល់វាទៅដល់ចំណុចអប្បបរមា ទាបបំផុត។
គណិតវិទ្យា
រូបមន្តមូលដ្ឋាន
Gradient descent ធ្វើបច្ចុប្បន្នភាព parameters ដោយប្រើរូបមន្តសាមញ្ញនេះ:
ដែល:
- តំណាងឱ្យ parameters ដែលយើងកំពុង optimize (តើតម្លៃ Parameter ណាមួយដែលយើងកំពុងស្វែងរក ដែលធ្វើឲ្យអនុគមន៍ មានតម្លៃតិចបំផុត)
- គឺ learning rate (អត្រាបោះជំហាន ឬ ទំហំជំហាន)
- គឺ cost function ឬ objective function ដែលយើងចង់ រកតម្លៃ ណាដែលធ្វើឲ្យ មានតម្លៃតូចបំផុត
- គឺ Gradient(ដេរីវេ | Derivative) នៃ ជាអនុគមន៍នៃ
ការយល់ដឹងពី Gradient: ពីសាមញ្ញទៅ កំរិតខ្ពស់
តោះបកស្រាយនិមិត្តសញ្ញា gradient (ហៅថា "nabla" ឬ "del") ដោយបង្កើតពីករណីសាមញ្ញបំផុត។
ករណី 1: អថេរតែមួយ (Parameter មួយ)
នៅពេលយើងមាន parameter តែមួយ, gradient គឺគ្រាន់តែជា ដេរីវេ:
Derivative ប្រាប់យើងថា: "ប្រសិនបើខ្ញុំបង្កើន បន្តិចបន្តួច តើ ផ្លាស់ប្តូរប៉ុន្មាន?"
ឧទាហរណ៍: សម្រាប់ :
- ប្រសិនបើ , នោះ → អនុគមន៍កំពុងកើនឡើង, ទៅខាងឆ្វេង (បន្ថយ )
- ប្រសិនបើ , នោះ → អនុគមន៍កំពុងថយចុះ, ទៅខាងស្តាំ (បង្កើន )
- ប្រសិនបើ , នោះ → យើងស្ថិតនៅចំណុចអប្បបរមា!
ករណី 2: អថេរពីរ (Parameters ពីរ)
នៅពេលយើងមាន parameters ពីរ និង , gradient ក្លាយជា vector មួយមានធាតុផ្សំពីរ:
Partial derivative នីមួយៗ សួរថា: "ប្រសិនបើខ្ញុំផ្លាស់ប្តូរតែ (រក្សា អថេរផ្សេងទៀតថេរ), តើ ផ្លាស់ប្តូរប៉ុន្មាន?"
ឧទាហរណ៍: សម្រាប់ :
នៅចំណុច :
Vector នេះចង្អុលទៅទិសនៃការឡើងចម្រោងបំផុត។ យើងទៅក្នុងទិសផ្ទុយ (ដក វា) ដើម្បីចុះក្រោម!
ករណី 3: អថេរច្រើន (ករណីទូទៅ)
សម្រាប់ n parameters , gradient គឺ n-dimensional vector:
ធាតុផ្សំនីមួយៗប្រាប់យើងថា តើ ប្រែប្រួលប៉ុន្មាន ចំពោះការផ្លាស់ប្តូរនៃ parameter ក្នុងចំណោមណាមួយនោះ។ នេះគឺជាអ្វីដែលយើងត្រូវដឹង ដើម្បីកំណត់ថា តើយើងគួរកែ parameter នីមួយៗទៅទិសណា!
ចំណុចសំខាន់: មិនថាអ្នកមាន parameter 1 ឬ 1 លាន, គំនិតគឺដូចគ្នាតេ: គណនាថា តើ parameter នីមួយៗប៉ះពាល់ដល់ cost ប៉ុន្មាន, បន្ទាប់មកកែសម្រួលវាក្នុងទិសផ្ទុយ។
ឧទាហរណ៍ពេញលេញ
តោះមើល gradient descent ក្នុងការដំណើរការជាមួយករណីសាមញ្ញបំផុត: អថេរតែមួយ។
សូមគិតរកការបន្ថយទៅប្រកដដែលអប្បបរមាសម្រាប់អនុគមន៍ quadratic:
Gradient (ដេរីវេ) គឺ:
យើងអាចសរសេរ Gradient descent algorithm ជា:
ចាប់ផ្ដើមនៅ ជាមួយ learning rate :
Iteration 1 (ជំហានទី 1):
Gradient វិជ្ជមាន (10 ជំរាលឡើងខាងលើ), ដូច្នេះយើងបានធ្វើចលនាទៅខាងឆ្វេង (បន្ថយ )
Iteration 2 (ជំហានទី 2):
នៅតែជា gradient វិជ្ជមាន, កំពុងតូចទៅ, ដូច្នេះជំហានតូចជាង
Iteration 3 (ជំហានទី 3):
Pattern បន្ត: នៅពេលយើងចូលទៅកាន់ចំណុចអប្បបរមា, gradient កាន់តែតូចទៅៗ, ដូច្នេះជំហានរបស់យើងតូចជាងដោយស្វ័យប្រវត្តិ!
ជាមួយនឹងជំហាននីមួយៗ, យើងចូលទៅកាន់ជិតនូវចំណុចអប្បបរមានៅ ។ សូមកត់សម្គាល់ថា ជំហានតូចជាងដោយធម្មជាតិ នៅពេល gradient ថយចុះក្បែរនូវចំណុចអប្បបរមា!
គំនិតសំខាន់ៗ
Learning Rate | អត្រាបោះជំហាន ឬ ទំហំជំហាន
Learning rate មានសំខាន់សំខាន់:
- ទំហំពេក: យើងអាចរំលងចំណុចអប្បបរមា ឬ បង្កើតការវិលជុំមិនចប់ (មិនដល់គោលដៅ)
- ទំហំតូច: ចំណាយពេលច្រើនហើយ កម្រដល់គោលដៅ
- សមស្រប: ទៅដល់គោលដៅបានយ៉ាងមានប្រសិទ្ធភាព
តោះធ្វើតេស្តជាមួយ learning rates ផ្សេងៗ ហើយមើលថាវាអាចប៉ះពាល់ដល់ការចូលរួមគ្នា (convergence) យ៉ាងដូចម្តេច!
សិក្សាទំហំជំហាន
ស្ថិតិ
ការកំណត់រហ័ស
ខ្សែកោង
Loss (កាន់តែតូចមានន័យថា កំពុងខិតជិតអប្បបរមា)
អំពី ទំហំជំហាន
ទាបពេក (< 0.05)
ការប្រមូលផ្តុំយឺតណាស់។ ក្បួនដោះស្រាយត្រូវការការធ្វើម្តងទៀតច្រើនដើម្បីឈានដល់អប្បបរមា ប៉ុន្តែផ្លូវមានស្ថេរភាព។
ល្អបំផុត (0.05 - 0.3)
តុល្យភាពល្អរវាងល្បឿននិងស្ថេរភាព។ ធ្វើឱ្យប្រមូលផ្តុំយ៉ាងមានប្រសិទ្ធភាពដោយមិនលើសពីអប្បបរមា។
ខ្ពស់ពេក (> 0.5)
អាចលើសពីអប្បបរមា ឬបែកខ្ញែក។ ក្បួនដោះស្រាយក្លាយជាមិនមានស្ថេរភាពហើយអាចនឹងមិនប្រមូលផ្តុំទេ។
ប្រភេទនៃ Gradient Descent
1. Batch Gradient Descent
ប្រើទិន្នន័យទាំងអស់ ដើម្បីគណនា gradient:
ដែល ត្រូវបានគណនាលើឧទាហរណ៍បន្តុបកយសិក្សាទាំងអស់។
2. Stochastic Gradient Descent (SGD)
Update parameters ដោយប្រើឧទាហរណ៍បន្តុបកយសិក្សាមួយម្តងមួយ ក្នុងមួយពេល:
3. Mini-batch Gradient Descent
ជាការប្រទាក់ចូលគ្នា: ប្រើbatch តូចមួយ នៃឧទាហរណ៍:
ដែល គឺ batch size។
ចំណុចរួមតូច (Convergence)
Gradient descent ចូលរួមគ្នា នៅពេល gradient ក្លាយជាតូចបំផុត:
ដែល គឺតម្លៃ threshold តូចមួយ។
បញ្ហាប្រឈម
- Local Minima: Algorithm អាចជាប់គាំងនៅ local minima ជំនួសឱ្យការស្វែងរក global minimum
- Saddle Points: ចំណុចដែល gradient រកឃើញថាសូន្យ ប៉ុន្តែមិនមែនជាចំណុចអប្បបរមា
- Plateau Regions: តំបន់ដែល gradient មានទំហំតូចបំផុត ធ្វើឱ្យការសិក្សាយឺត
ការអនុវត្តន៍ក្នុងពិភពលោកជាក់ស្តែង
Gradient descent ត្រូវបានប្រើដើម្បីបណ្តុះបណ្តាល:
- Neural Networks: ការ Optimize parameters រាប់លាន
- Linear Regression: ការស្វែងរក best-fit line
- Logistic Regression: បញ្ហា classification
- Support Vector Machines: ការស្វែងរក optimal hyperplanes
Gradient Descent ក្នុង Deep Learning
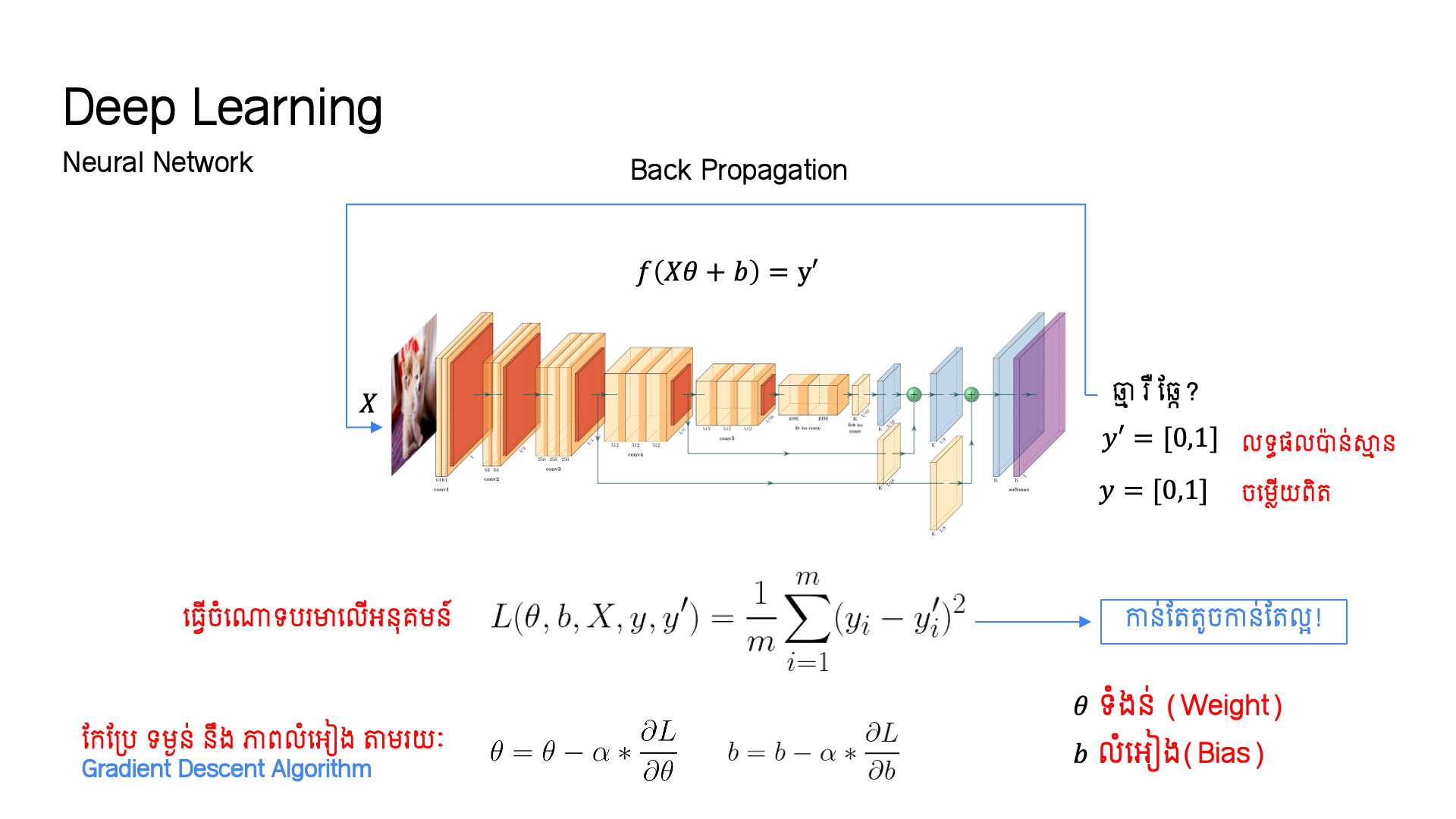
Deep Neural Network ប្រើ Gradient Descent ដើម្បីបណ្តុះបណ្តាលទម្ងន់ (weights) ក្នុង layers ផ្សេងៗ
រូបភាពខាងលើបង្ហាញពី Deep Neural Network — ប្រភេទ Neural Network ពេញនិយមមួយ ដែលប្រើ Gradient Descent ដើម្បី optimize cost function។
ក្នុង Deep Learning:
- Input Layer ទទួល data (ឧ. pixels នៃរូបភាព, ពាក្យ, លេខ)
- Hidden Layers ជ្រើរើសធ្វើ feature extraction — ស្វែងរកគំរូ (patterns) ស្មុគស្មាញ ពីទិន្នន័យ
- Output Layer ផ្តល់ការទស្សន៍ទាយ (prediction) ចុងក្រោយ
- Weights (ទម្ងន់) ក្នុង connections នីមួយៗ គឺជា parameters ដែល Gradient Descent ត្រូវ optimize
ក្នុងអំឡុងពេល Training:
Network មួយ មាន neurons រាប់លាន → weights រាប់លាន → gradient vector មាន រាប់លាន dimensions — ប៉ុន្តែ Gradient Descent ដំណើរការដូចគ្នានឹង 1D ដែរ: update ក្នុងទិស opposite នៃ gradient!
អនុវត្តក្នុង Python
ខាងក្រោមជាការសរសេរកូដ Python ដោយមិនប្រើ ML libraries ណាមួយ។ Code block នីមួយៗ ត្រូវតទៅនឹងរូបមន្ត math ខាងលើ — ជួរ highlighted ជា formula ចម្បង។
ជំហានទី 1 — Cost Function និង Gradient
# J(θ) = θ² → អនុគមន៍ដែលយើងចង់ minimize
def cost(theta):
return theta ** 2
# ∇J(θ) = dJ/dθ = 2θ → derivative (gradient) របស់វា
def gradient(theta):
return 2 * theta
ជំហានទី 2 — Update Rule
def update(theta, alpha):
grad = gradient(theta) # ① គណនា ∇J(θ)
return theta - alpha * grad # ② អនុវត្ត θ_new = θ_old − α·∇J(θ)
ជួរទី 3 គឺ formula update rule ខាងលើ សរសេរដោយផ្ទាល់ជា Python។
ជំហានទី 3 — Loop រហូតដល់ Convergence
Run updates រហូតដល់ — នៅពេល gradient ស្ទើររកឃើញថាសូន្យ:
def gradient_descent(theta_init, alpha, epsilon=1e-6, max_iters=1000):
theta = theta_init # θ₀ — ចំណុចចាប់ផ្ដើម
for i in range(max_iters):
grad = gradient(theta) # ∇J(θ) = 2θ
if abs(grad) < epsilon: # ឈប់: |∇J(θ)| < ε
print(f"Converged at iteration {i}")
break
theta = theta - alpha * grad # θ_new = θ_old − α·∇J(θ)
if i < 5:
print(f" iter {i+1:2d}: θ={theta:.5f} J={cost(theta):.5f} ∇J={grad:.5f}")
return theta
# ស្របតាម ការគណនា manual ខាងលើ: θ₀ = 10, α = 0.1
theta_min = gradient_descent(theta_init=10.0, alpha=0.1)
print(f"\nMinimum at θ = {theta_min:.8f}")
Output — ស្របតាម iterations manual ខាងលើ:
iter 1: θ= 8.00000 J=64.00000 ∇J=20.00000
iter 2: θ= 6.40000 J=40.96000 ∇J=16.00000
iter 3: θ= 5.12000 J=26.21440 ∇J=12.80000
iter 4: θ= 4.09600 J=16.77722 ∇J=10.24000
iter 5: θ= 3.27680 J=10.73742 ∇J= 8.19200
Minimum at θ = 0.00000001
ជំហានទី 4 — Linear Regression: Parameters ពីរ
សម្រាប់ model , cost function ប្រើ mean squared error:
ជាមួយ partial derivatives:
import numpy as np
def linear_regression_gd(X, y, alpha=0.01, epochs=500):
m = len(y)
w, b = 0.0, 0.0 # θ = [w, b] — initialize ទៅ zero
for epoch in range(epochs):
y_pred = w * X + b # forward pass: ŷ = w·X + b
error = y_pred - y # residuals: ŷ − y
dw = (2 / m) * np.dot(error, X) # ∂J/∂w = (2/m) Σ (ŷ−y)·x
db = (2 / m) * np.sum(error) # ∂J/∂b = (2/m) Σ (ŷ−y)
w = w - alpha * dw # w_new = w_old − α·∂J/∂w
b = b - alpha * db # b_new = b_old − α·∂J/∂b
if epoch % 100 == 0:
loss = np.mean(error ** 2) # J(w,b) = (1/m) Σ (ŷ−y)²
print(f"Epoch {epoch:4d}: loss={loss:.4f} w={w:.4f} b={b:.4f}")
return w, b
# y = 2·x → model គួរ converge ទៅ w≈2, b≈0
X = np.array([1.0, 2.0, 3.0, 4.0, 5.0])
y = np.array([2.0, 4.0, 6.0, 8.0, 10.0])
w, b = linear_regression_gd(X, y)
print(f"\nFitted: ŷ = {w:.4f}·x + {b:.4f}")
ជួរ highlighted 7–12 ទំនាក់ទំនងដោយផ្ទាល់ទៅ formulas:
- ជួរ 7–8: forward pass និង residuals
- ជួរ 9–10: partial derivatives និង
- ជួរ 11–12: gradient descent update rule
ជំហានបន្ទាប់
នៅពេលអ្នកយល់ដឹង gradient descent, អ្នកអាចស្រាវជ្រាវ Algorithms បន្ថែមដូចជា:
- Momentum: បន្ថែមល្បឿនទៅក្នុងការ update
- Adam: Adaptive learning rates សម្រាប់ parameter នីមួយៗ
- RMSprop: គ្រប់គ្រង sparse gradients បានល្អជាង